|
Documentation for 3.26
Files written by the System Under Test
Monitoring files that are created, edited and deleted by the tests
By default, the standard output of the system under test will
be collected to a file called "stdout.<app>" and the
standard error will be collected to a file called "stderr.<app>"
(or "output.<app>" and "errors.<app>" with the classic naming scheme: see the guide to files and
directories). Any other files that might be written by the system under test will be ignored.
However, it is possible to tell TextTest to "collate" individual files
and compare them in a similar way to how it compares standard output and standard error.
It is also possible to tell it to create an additional file which will list all files that were created, edited
or deleted by the system under test (a "catalogue" file), in case comparing every single file is overkill.
This can be done by specifying the config file entry
"collate_file". This entry is a dictionary of lists: on the left hand side you make
up a name which TextTest will use to identify the file, and on the right-hand side you
tell it how to find the file. For example
[collate_file]
edited_file:file.txt
file_from_subdir:subdir/*.dump
This will cause TextTest to look for "file.txt" in your sandbox directory and if it is found and has been edited by the test, copy it to "edited_file.<app>" and use it as part of the test baseline in future. It will also look for any file matching the UNIX path expansion "subdir/*.dump" (again relative to the sandbox) and copy it to "file_from_subdir.<app>" in a similar way.
The paths identified on the right hand side here should in principle never be
absolute paths : they should be relative, implicitly to the sandbox directory.
This is because your tests will otherwise have global side effects - making them
harder to understand and more prone to occasional failure,
particularly if run more than once simultaneously.
Note that this ordering can seem counter-intuitive, in effect
you are asking TextTest to copy the text file on the right to the location identified
on the left. You might expect the source to be named before the target, but many different config
dictionary entries use these TextTest names for result files as
keys so this one works the same for consistency.
Note also that TextTest will only collate files that were created or
modified by the test run. Unchanged files will not be picked up even if they
match a source pattern.
As in the example, standard UNIX file pattern matching (globbing)
may be used in the path to the source file. This simply means that the
exact name of the file that will be produced may vary, but whatever file matches the
pattern will be copied and given the same name each time by TextTest. If multiple files
are found by this method, the first one
alphabetically will be used. See below for how to collate multiple files at once.
It's also possible to provide multiple patterns or
names to look in for this situation, where the names of
the produced files vary in such a way that writing a pattern isn't
possible. The standard syntax for a config file list is used.
If comparison of a collected file is not desired for any
reason, it can be added to the config file list entry
“discard_file”. The most common usage of this is to
disable the collection of standard output and/or standard error, for example
discard_file:stdout
discard_file:stderr
(NOTE: you may need to write "output" and "errors" instead of "stdout" and "stderr" if
your test suite is using the classic naming scheme, which it probably is if it was created with 3.18 or earlier).
This can be done by using asterisks ("*") in the TextTest name (or "target pattern").
No other types of UNIX-style file pattern matching are allowed here. All files written by the test that match the “source
pattern” will be collated. E.g. suppose we have the following entry in the config file:
[collate_file]
dumped_data*:data*.dump
Suppose also that the latest run produced data1.dump and
data2.dump. These files will then both be collated, to
dumped_data1.<app> and dumped_data2.<app> respectively.
This works in general by replacing the asterisks in the target pattern with whatever was matched by the corresponding
pattern element in the source pattern. In this case the "*" on the right hand side was matched by "1", so that string
replaces the "*" on the left-hand side to form the new name. If patterns appear in both file names and directory
names in the source pattern, those from the file names will be used before those in the parent directory names.
Any left-over matches will simply be thrown away. If there are more asterisks on the left hand side than there are
patterns on the right-hand-side, any remaining ones will be replaced by the string "WILDCARD", which is intended
as a warning that the pattern isn't quite right.
The restrictions on patterns and the assumptions of common stems which were present in TextTest
versions up to 3.15 have now been removed. Pretty much any (sensible) pattern should now work. The following
is for example a quick way to collate all files and preserve their names:
[collate_file]
*:*
If the file you refer to via "collate_file"
is not plain-text or needs to be pre-processed
before it can easily be compared, you can tell TextTest to run
an arbitrary script on the file. This script should take a
single argument (the file name to read) and should write its
output to the standard output. You do this by specifying the
composite dictionary entry “collate_script”, which
has the same form as “collate_file” except the value
should be the name of the script to run. “collate_script” has
no effect unless “collate_file” is also specified for the
same file.
There are several ways that TextTest can find the script. Obviously
a full absolute path will work. If a relative path is given, TextTest will also look in its
own "libexec" directories where its standard collate scripts live : to avoid
mixing your scripts with the standard ones you can create a directory
"site/libexec" and scripts in there will be found also. The scripts can also just be
placed somewhere on your PATH, which will now work on all platforms.
Note also that you can specify several scripts in a list, in which case they will be chained
together using a pipe. On Windows, this chaining will however not work with scripts
found only via PATH as the Windows shell cannot handle this piping.
Anything written on standard error by the script will appear in a popup window. To avoid
unnecessary popups you should either ensure it writes nothing there, or if this is not
possible, use the "suppress_stderr_text" setting which allows you to filter out particular
messages as normal.
Binary files should be identified as such by listing them
in the “binary_file” config file entry - this ensures that TextTest will check
whether they are identical but no attempt will be made to filter them or run a difference tool on them. Also
previews of them will not be shown in the TextTest GUI as this will likely not show anything useful.
If they differ, it's then up to the user to examine both files using whatever tools they have available to them.
If standard results have not already been collected for a
particular file produced when a test is run (as they won't be when you've just enabled the mechanism above)
, the file is reported under “New Files” and should be checked
carefully by hand and saved if correct. New files appearing is
also sufficient reason to fail a test, so every test should fail
the first time unless the expected results are imported
externally. The standard output and standard error are also treated this way.
In the same way, if files are not produced that are present
and expected in the standard results, these will be reported
under “Missing Files” and the test will fail.
Saving such a result will cause the missing files to be removed
from the standard results.
Sometimes a system will potentially create and remove a great
many files in a directory structure (TextTest itself is one
example!) Collecting and comparing every single file might be
overkill. Instead, you have the possibility to create a
catalogue file, which will essentially compare which files
(under the test's temporary directory)
are present before and after the test has run, and which files
and directories that were present before have been edited during
the test run.
It will then report what has been created, what has been
removed and what has been edited. This is done by setting the
config file entry “create_catalogues” to true. It
will generate result files called catalogue.<app>.
If no differences are found, this is noted briefly at the top of
the file : catalogue files are always created from version 3.6
and onwards.
Note that this feature can be used to aid test
data isolation also. In addition, you can request that the catalogue functionality
checks for processes that were created (leaked!) by the test. If
such processes are found to exist, they will be reported to the
catalogue file and automatically terminated by TextTest. This is
done by getting the SUT to log when it creates a process in a
predictable way. The text identifying the process created should
be provided in the “catalogue_process_string” config
file entry. TextTest will then search the result file indicated
by “log_file” for matches with this string, and
assume the process ID immediately follows it. If the process is
found to be running, it will be reported to the catalogue file
and terminated.
This is controlled by the dictionary entry
“failure_severity”, and takes the form:
[failure_severity]
<texttest_name>:<severity>
<severity> here is a number, where 1 is the most severe
and increasing the number means decreasing the severity. If the
entry is not present, both “stdout” and “stderr”
files will be given severity 1, while everything else will have
severity 99.
The severity has two effects on how TextTest behaves:
- When multiple files are found to be different, the
difference is always reported in the dynamic GUI “details”
column as a difference in the most “severe” file
found to be different.
- If a severity 1 file is found to be different, the whole
line will turn red, otherwise only the “details”
column will turn red.
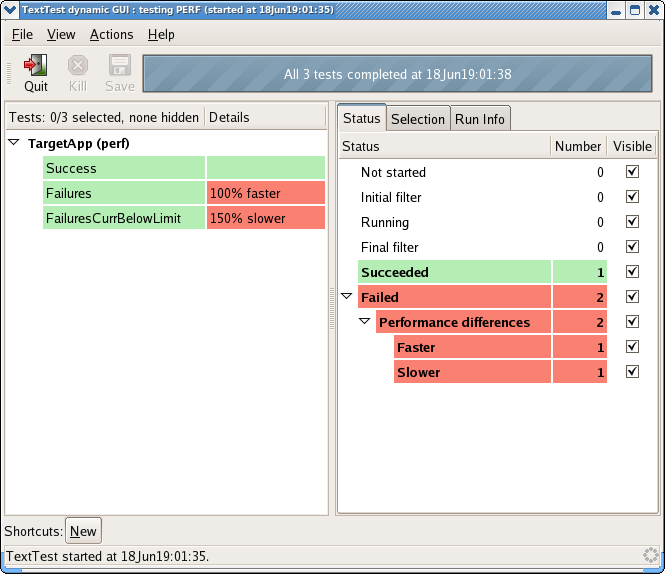
As an example, the test below has failed in “performance”,
which is a severity 2 file. If the text on standard output had also been
different, the whole line on the left would be red and the
details would report “stdout different(+)”.
|