|
Documentation for 3.27
Other versions: trunk 4.3 4.0 Older...
Running TextTest Unattended
A Guide to Batch Mode
It can be very useful to have TextTest run unattended and regularly
and provide the results in an email, an
HTML report or on your continuous integration server rather than have one of the
interactive
user interfaces present. That is the purpose of “batch
mode”. To select batch mode, provide the command line
option “-b <batch_session>” or fill in the
“Run Batch Mode Session” tab under “How to
Run” in the static GUI. In general, you will probably want
to start such batch runs via a script, for example using crontab
on UNIX, or from a continuous integration server. TextTest can also produce results
in a format compatible with JUnit, which means popular CI servers
(for example Jenkins) can display them in the same
way as unit test results. As seen later, TextTest now also integrates directly with Jenkins and can provide
information from it in its batch report The batch mode “session” is simply an identifier
that defines a particular sort of batch run. Most of the batch
mode configuration can be defined per session. Any identifier at
all can be provided, and if no configuration is recognised for
that session name default settings will be used. All of the
batch mode config file settings that start with “batch_”
(described below) are “composite dictionary entries”
with the batch session names as keys, it is recommended to read
the file
format documentation for what this means.
TextTest will return an exit code of 0 if all tests succeed or have known bugs.
If any tests fail (have differences) it will return an exit code of 1. If any tests have performance or memory differences,
but none have "failed properly", then it will return an exit code of 2.
These codes will be interpreted directly by CI servers, and you can also easily write a wrapper script to take appropriate actions.
The HTML report is now the most widely used and feature-rich of TextTest's batch reports.
To get an idea what this looks like, look at this
small example.
Each day's results correspond to a column, while each test has a row. The
results can be explored by clicking around. Note the new (in 3.22) toolbar at the top, which allows you to hide or show tests.
The text box allows you to show only tests containing a certain string or regular expression. The coloured toggle buttons
allow you to hide tests in a particular category: this uses the most recent result for each test. You can also hold down
control and click them to show only that category.
For a real such page in active use,
check out the nightly runs of TextTest's self tests page, which is
updated every day with the latest status.
In order to store the information from the batch runs, the
config file entry “batch_result_repository” should
be set to a directory under which batch results can be stored.
Results are then stored per test and run and are never
overwritten: to recreate results for a particular run identifier it is
necessary to explicitly remove the previous ones, either
manually or via the archiving script described below.
Test runs are identified by providing the "-name" option on the command line when running. If this is not provided, today's date will
be used as an identifier, which will limit you to one run per day.
For the location of the actual reports, set the config file
entry “historical_report_location” to another
directory. Both of these are composite dictionaries as described
above so both can be varied per batch session. In order to
actually generate the report, you will need an additional TextTest run with the -coll flag (see below)
which will not run any tests but will instead rebuild all the reports from scratch based on what is in the repository
and even in archived files (see below)
By default, each application will be shown on a separate page named after that application.
An index page ("dashboard") will be created at the top level which will link to all the application
pages and briefly indicate how many tests are succeeding and how many are failing. This index
page is automatically generated when running with the "-coll" flag, but can also be regenerated
alone : using -s batch.GenerateSummaryPage -b <batch_session>. The form of the page
is determined by the file "summary_template.html" which will be copied to your repository
the first time you build the pages. This can then be edited to e.g. add other relevant information
and links to your dashboard page.
If you install "Matplotlib" (version 0.98 or later), a clickable graph that shows a summary of the test behaviour
over time will be added at the top of the page. These graphs can also be generated alone
by using -s batch.GenerateGraphs -b <batch_session>.
Graphs generated in this way will currently include all runs which exist in the HTML pages.
You can also then set "historical_report_piechart_summary" to "true" which will cause the
little result summary tables to be replaced by Matplotlib pie charts if you think that looks nicer.
In order to generate webpages from archived data back to a given date,
you can use "-collarchive date". It should always be used together with the "-coll web" option.
I.e. texttest -a myapp -b myjob -coll web -collarchive 22Jan2012
Sometimes though it can be useful to have several applications directly on the same page, especially
if they don't have so many tests each. In this case you can set the config file entry
"historical_report_page_name": the name given will be used as the title of the HTML report
and all applications with the same value will appear on the same page. In this case no index/dashboard
page will be generated.
The colours in the site are also configurable: use the config
file dictionary setting “historical_report_colours”. To
see how to set this, look at the config
file table and pattern match on the default value. Note that you can now configure the run header colours per day of the week
if you wish to highlight runs made, for example, at the weekend when more tests may be run.
If you start your tests from the continuous integration software Jenkins, TextTest will notice this and will try to establish what has
changed in Jenkins since the last build. The resulting HTML report will then have an additional row marked "Changes", which will create links with the names of people who have committed
changes, linking directly to the Jenkins pages with the changes. If you are also using Jira for bug tracking it will
also identify bug IDs in the commit messages and link those directly also.
This functionality relies on Jenkins fingerprinting,
which you need to enable. Another complication is that the fingerprints for a job are written only after it and all its post-steps have exited,
so to generate the report with correct changes information from the same job requires starting TextTest in the background and decoupling
it from Jenkins. You do this as follows, from within the Jenkins job:
export BUILD_ID=none # Stops Jenkins from killing this process when the job exits
texttest -coll web -b <batch_session> &
You can also tell it to highlight changes in particular artefacts produced as part of the Jenkins build, in case these are imported from outside the Jenkins build periodically and so changes in them
aren't picked up via normal means. You then set, for example
[batch_jenkins_marked_artefacts]
nightjob:mypackage.mycomponent
This will cause the plugin to check if the artefact mypackage.mycomponent has been changed, and if it has, add a message "mypackage.mycomponent was updated" to the Changes row.
Like all other batch settings this can be configured based on the batch session ID.
A new and rather experimental feature is to double-check Jenkins' fingerprint data. When simultaneous builds are enabled the
fingerprints are sometimes wrong, as they are only based on the latest file for a particular component when the build is made.
You can achieve this by setting "batch_jenkins_archive_file_pattern" to a path: this will then look in the workspace for the artefacts
matching the archived version of a particular build and try to highlight when these differ from what Jenkins thinks they are.
If you're making use of TextTest's performance and memory testing features it can be useful to have this information displayed directly in the table also. To do this you can set the config setting "historical_report_resources". For example:
[historical_report_resources]
nightjob:performance
nightjob:memory
would cause an additional row for performance and an additional row for memory to be generated for every test that had such information (with "-b nightjob" in this case, of course).
Such rows can be noticed as the data in the cells is right-justified rather than left-justified, and there is no "row header" cell. The text will show the difference in that measurement, even if it was not sufficient to fail the test. This replaces the earlier separate reports for this which existed in TextTest 3.26 etc.
Up to TextTest 3.12 there were two "subpages" produced as part of the HTML report: one
showing the last six runs and one showing all of the runs. This is now completely configurable.
The names of the subpages produced are controlled by the config file setting "historical_report_subpages",
which by default will contain only "Last Six Runs" which works as before. It is however easy to remove
this page via the {CLEAR LIST} mechanism.
Such a subpage will contain a subselection of the runs present in the repository. If no subselections are specified,
all the runs will be included. So restoring 3.12's "All" page is just a matter of adding:
historical_report_subpages:All
There are two ways of subselecting the tests. You can specify a cutoff point, similar to "Last Six Runs",
by specifying the dictionary entry "historical_report_subpage_cutoff". This should be keyed on the name of the
subpage specified as above, and the value is the number of runs to include. You can also filter on days of the
week, by providing a list of weekdays to include in the entry "historical_report_subpage_weekdays", which is also
keyed on the name of the subpage. So for example, if we wanted to include a page with the last fortnight's results
and a page only showing runs done at the weekends, we could do:
historical_report_subpages:Last Fortnight
historical_report_subpages:Weekend
[historical_report_subpage_cutoff]
Last Fortnight:14
[historical_report_subpage_weekdays]
Weekend:saturday
Weekend:sunday
After a while, very old test results in the repository cease
to be interesting and can safely be archived. This is done via
the script batch.ArchiveRepository, with arguments 'after' and
'before' for the time period to archive (The
batch session to do it on is provided in the normal way via -b on the command line,
it defaults to all known sessions if none is provided). The
dates should be in the same format as the dates on the pages,
e.g. 21Jan2005. The generation only uses files from the last month by default,
but even so just searching for the files can take a while if there are a lot of them.
It doesn't actually delete things but creates a tarball in the location specified by
"batch_result_repository", named by the date provided. By generating using the "-collarchive"
flag (see above) you can include this data when generating the pages afresh.
If you have specified a weekday-specific page using "historical_report_subpage_weekdays" (see above)
it can be useful to keep a longer time period for those weekdays, so that this page is not unduly truncated.
This can be done with the parameter "weekday_pages_before", with the same format as above. So for example
if on March 1st you decide to keep all data for February but only the weekday pages for January, you would specify
texttest -s "batch.ArchiveRepository before=01Feb2013 weekday_pages_before=01Jan2013"
It is also possible to archive the actual HTML pages, as well as the stored test results. It takes a lot
longer for there to be so many of these that it's a problem (a year or even two of data is no problem),
but even so it has been known to be useful to archive them after 10 years or so...
This is done at the granularity of 1 month, using the script batch.ArchiveHTML, for example:
texttest -s "batch.ArchiveHTML before=Jan2012"
The config file entry “batch_timelimit”, if
present, will run only tests which are expected to take up to
that amount of time (in minutes). This is of course only useful
if performance testing is enabled for
CPU time. More generically, you can use the “batch_filter_file”
entry to identify filter files
to be associated with a particular batch run. These can either
contain a list of tests or search criteria to apply and can be
edited using the static GUI. In this context it can be useful to
note that such filter files can contain application and
version-specific suffices in case similar criteria imply
different tests for different applications: this allows the same
entry for batch_filter_file to indicate different tests for
different applications and versions.
If certain versions should be run automatically as part of a batch
mode run without needing to explicitly specify them on the command line,
the entry “batch_extra_version” can be used for this purpose. This
is a more specialised version of the “extra_version” setting.
If you wish to select the tests that will be run by a batch run without actually running it,
e.g. to load them into the GUI or to run them not in batch mode, you can use the command line
option "-bx <batch session name>" to achieve this. This has the effect of looking up
and applying the settings configured for "batch_timelimit", "batch_extra_version" and "batch_filter_file".
If the entry “batch_use_version_filtering” is set
to “true”, all versions are assumed to be disabled
unless explicitly enabled by being included in the
“batch_version” list setting. The point of this is
in the presence of multiple test applications and multiple
releases of the system: a single run of TextTest can be started
with a particular version identifier and each application can
decide in its config file if it wants to run tests for that
version of the system. This is generally easier than trying to
set up separate nightjob runs for each application.
Both of these things act in concert with any test
selection filters selected on the command line or from the
static GUI. As described there, only tests which satisfy all
filters present will be selected.
Many teams use a CI server and keep up-to-date information about test status available
to all developers at all times. In order to integrate texttest with these systems,
there is an option “batch_junit_format”
which allows you to generate
texttest results in the same format that JUnit uses.
Most CI servers will understand
this format, and this makes it easy to plug TextTest into existing build systems.
The drawback of the JUnit format results is that some information is lost compared with the other formats. You will
likely want to have the email as well. The CI server will give a basic indication
that something is wrong, which you then investigate by looking at the email and/or
reconnecting to the failed tests.
If you set “batch_junit_format” in your config file, then
texttest will produce a folder "junitformat" in the run directory (under TEXTTEST_SANDBOX),
and under there a subfolder for each application's test results.
Each folder contains one xml file per test. Ant has a task "junitreport" that can collect
all the xml files for one application together and produce a composite xml file and html report.
There is an additional option “batch_junit_folder”
which allows you to specify a different folder, (instead of "junitformat"), where the xml files should be written.
The Junit XML files have a space for the time used by the test. By default, this will be filled with the contents of the "performance"
file, if this is collected (see here
for details if how this works). Sometimes, however, you might want some other time value extracted from a log file placed in this field,
in which case you should set the "default_performance_stem" field accordingly. So if you collect the resource
"my_cpu_usage", you ensure this ends up in the Junit XML file by doing
default_performance_stem:my_cpu_usage
(This replace batch_junit_performance from TextTest 3.23 and earlier)
Note: if you
are using TextTest with Java, you may want to look at this page for more tips.
None of the reports described are enabled by default, so it's possible to just use batch mode runs and monitor their console output. This is particularly useful in continuous testing environments such as ZenTest. However, with everything being black and white it can be hard to notice when tests succeed and fail. You can therefore provide the "-zen" option on the command line which will produce green and red console output when appropriate. This works on both POSIX and Windows, albeit in totally different ways internally.
The email report was TextTest's original batch report and is not really recommended in the first instance any longer.
It's recommended to try to use the HTML report first. If you already have the HTML report enabled though,
the email will just contain a summary of the results and some links to the relevant parts. If you don't, it will contain
a lot more detailed information.
To enable it, set "batch_recipients" to a valid email address or several.
In the case where the HTML report is already enabled, the generated links will point directly at the directory indicated by
"historical_report_location", and will start with "file://". Obviously there is no guarantee these will work in somebody's mail reader,
so to convert them to URLs there is a config setting "file_to_url". This can usefully be set as a
site-specific config file
as it will probably be the same for everyone on the same network. For example
[file_to_url]
/path/to/report:http://ourserver.com/report
[end]
will cause links beginning with file://path/to/report to instead use the given URL.
When using the email report alone in a multiple-developer project it is often useful to direct such
reports to a newsgroup, providing everyone the chance to see at
a glance what works and what doesn't. This will then generally
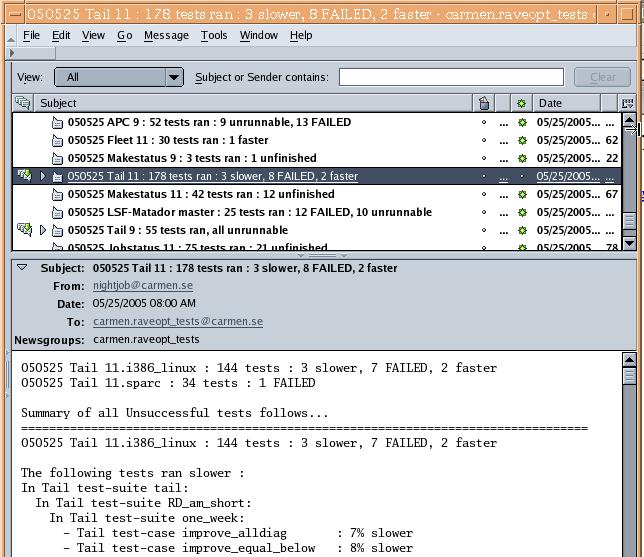
look something like this (example newsgroup viewed in mozilla):
As you see from this example, the title of the mail consists
of the date and a summary of what tests were run and what
happened to them (for the application “Tail”, in
this case). Note that the date provided may not be quite what you expect as it changes at 8am local time,
so runs before this time will be assigned the previous day's date. This is because the functionality is often
used for "nightjobs" which may start either side of midnight, which would cause confusion if the date used
was the actual local date.
If the -name option is provided to the run on the
command line, that name is used to define the run instead of the
date. In general, use -name to test actual named releases, and
the default date-functionality with nightjobs. (Note that "-name" also affects the HTML report above, and
runs done via the GUI, see here
for information about this.)
The body of the mail contains two further sections, one which
summarises exactly which tests failed and a further section
which endeavours to give some details as to why they failed.
These sections can be explored or ignored depending on how
involved the reader is in the project. Managers will generally
only need to look at the subject lines...
The name of the application, as provided here, can be
configured via the config file entry “full_name”. By
default a capitalised version of the file extension used for the
application will be used here, but this doesn't always look so
nice in reports.
The “details” section consists of the textual
previews as generated by the dynamic GUI's “text info”
tab when a test fails. It can be configured in the same way.
In addition, it can be useful to configure the maximum width of
lines allowed: some newsgroups have maximum line length limits
and you don't want test reports bouncing. This can be done via
the config file entry “max_width_text_difference”. You can also configure it so that mail is only sent
if at least one test fails, set the config file entry “batch_mail_on_failure_only”
to "true". By default mail will always be sent irrespective of what happens. This uses
the same criteria as that which sets the exit code to 0: i.e. mail will also not be
sent if there are only succeeded tests and known bugs.
Where the mail is sent to is controlled by the config file
entry “batch_recipients”. This can be configured per
batch session, and may be a comma-separated list for multiple
recipients. The sender address can be controlled by the
“batch_sender” config file entry
The SMTP server to use for sending mail
can also be configured via “smtp_server”. By default
it will assume that no authentication is required, unless the
"smtp_server_username" setting is defined. If so, it will attempt
to login with that username and the password defined by "smtp_server_password"
before attempting to send mail.
All of these will need to be configured on Windows as no
defaults are provided. On UNIX, the SMTP server defaults to
“localhost” and the sender address defaults to
“$USER@localhost”, so it is generally
only necessary to configure the recipients.
When many versions of the system under test are active, and
many different hardware platforms are used, you may want to test
the system on all of these combinations. This can lead to a
great many test runs and consequently a lot of emails. It is
often easier to read these if they are collected into a single
larger email: otherwise it is hard to get an overview of what is
happening.
To do this, set the config entry “batch_use_collection”
to "true" for the batch session in question. This will
ignore the email-sending settings and send the batch report to
an intermediate file. When all tests have been run in this way,
run the collection script by providing the "-coll" argument on the command
line. This will also build the HTML report described above, if that
is enabled. To build only the email report or only the HTML report,
you can also run with "-coll mail" or "-coll web" respectively. (The older
plugin script "batch.CollectFiles" is now removed from TextTest 3.26 onwards)
TextTest will then search for all such intermediate files
and amalgamate them into a single mail per application. If a
version is provided to this script via -v <version>, only
runs which ran with that version identifier will be collected.
This applies to the HTML report as well.
By default this collection procedure will find all batch runs that have currently
stored their results under the root temporary directory. There are two ways in
which this can be configured to handle errors in the processes that are supposed to
create these runs.
For a start, you can set the config entry "batch_collect_max_age_days"
which will ensure that no batch run older than the given number of days will be picked up
and reported. This is useful in case the expected batch run has not been run for some reason,
otherwise the results of the previous run may be picked up and lead to confusion.
Also, you can tell it what it should expect to find. By providing the entry "batch_collect_compulsory_version"
(which is a list), you can tell it to report an error if a batch run for a certain version was not found, thus making
it clearer if something has not run when it was supposed to. Both these settings are keyed on
batch session names as described above.
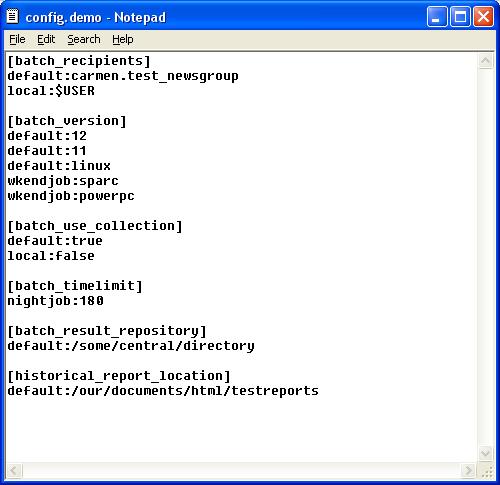
This config file configures TextTest so that:
- “-b local” will send email to the sender
directly
- “-b nightjob” will run all tests that take
up to 180 minutes (3 hours). It will only accept the version
identifiers “11”, “12” and “linux”
(if we also set “batch_use_version_filtering” to
true, which we didn't here...) It will write its results to an
intermediate collection file, where they can be collected
later.
- “-b wkendjob” will run all the tests that
there are. It will also accept the version identifiers “sparc”
and “powerpc” (evidently we want to test on more
flavours of UNIX at the weekends!). It will use collection in a
similar way to the “nightjob” session.
- All of these will write their results under the location
/some/central/directory, provided no previous results have been
calculated that day. When the collection is run, the files from
the 'nightjob' or 'wkendjob' sessions will be amalgamated and
mailed to the carmen.test_newsgroup mail address. The website
at /our/documents/html/testreports will also be regenerated
from scratch from the repository described above.
Batch mode's email report is all very well, but alone it
doesn't give you the power of the GUI to view results in detail
or to approve them if that would be appropriate. It can be very
useful to “reconnect” the GUI as if a batch run had
been run using it. To do this, select “Reconnect”
from the Actions menu in the Static GUI, which will bring up a
dialog where you can browse your file system to find the files
for the run. These files are the "sandbox" directories and will be located
under the location specified by the TEXTTEST_TMP environment variable for the batch run itself,
which defaults to ~/.texttest if you don't set it. They should not be confused with the
"batch_result_repository" location, used only for the HTML report.
(You can also provide the “-reconnect <directory>”
option on the command line to the dynamic GUI ("-g") or console interface ("-con")).
There are essentially two ways to select previous runs. Either
you explicitly select the run directory (it will be called something like "hello.version.13Aug171624.9856"),
or you leave the parent directory selected and provide a version filter in the “Version to Reconnect to”
field. This last possibility will then load in all runs that were run with that version identifier,
or some more specific version identifier: i.e. if you provide "foo" it will load runs for "foo.bar" and "foo.blah"
also if they exist. Not selecting either will load in every previous run that has left files in the relevant temporary
space.
There is a switch at the bottom which allows you to choose
between a quick re-display of what was displayed in the original
batch email report, and an option to recalculate the results
from the raw files. If for any reason the quick re-display isn't
possible, it may trigger a recomputation anyway.
The recomputation, whether explicitly requested (-reconnfull
on the command line has the same effect) or auto-triggered, will
take the raw output of the run reconnected to and reapply the
text filtering mechanisms to it, and also re-evaluate any
automatic failure interpretation
that could be triggered. This is useful if you have updated your
config file filters in the meantime and want to see if they are
applied correctly. It is, of course, a good deal slower than
simply re-reporting what was present before, as occurs by
default.
It is always hard to tell whether a test
is just about to finish or whether there is a neverending loop in the
code preventing it from doing so. In order to fix such cases one may specify a
“kill_timeout” (in seconds) in the configuration file,
in order to kill such test instances after a specified time. Please note
that it is wall clock time not CPU usage which is measured here.
One further use case for this option are programs which pop up
some “send bug report” window on crashing (this is often the case with executables
on Windows) and do not exit until the window has been clicked away.
With a “kill_timeout” at least the tests can continue although
you still may have to click away the window manually.
This option applies to the interactive modes as well but in batch mode
it is most useful.
By default, TextTest will attempt to kill the entire process tree
(that is a process and all processes started by it). On POSIX platforms this will send signals directly to the
processes, while on Windows it will call a Windows system tool called
"taskkill" which allows to kill a complete tree. This tool is available at least on WinXP and successors.
If "taskkill" is not found, the fallback is a system function which kills the process but no descendants.
To configure how this is done, you can set "kill_command" in your config file. The command you provide will be
called once with a single argument, the process ID. For example
kill_command:kill -s INT
is a common usage on POSIX, where a single SIGINT is sent to the process, which in this case is probably a wrapper script.
That can then trap the signal, maybe print some statistics, terminate server processes in the right order, and so on.
On Windows, an example which makes the tree kill on Windows XP less aggressive, would be to try something like
kill_command:taskkill /T /PID
which leaves out the /F meaning "force" from the default call but still has the /T for tree killing.
|